|
Processing TabTable of Contents
OverviewOnce a data collection Run has completed with 10 or more images, the data are automatically processed using ICEflow - an SSRL automated pipeline that runs several 3rd party data processing applications that provide quick feedback on the quality of each data set. Data processing run information and selected results are written to the Sample Database. Once the run information appears in the database, selected information is diplayed in the Processing Tab. Currently, autoPROC is used to run procesing for two different reolution cutoffs for each dataset. If autoPROC detects an anomalous signal it will spawn two new jobs with anomalous flags to optimize anomalous data processing. If the Processing Tab is not displaying processing information:
If a group does not want auto-processing results written to the Sample Database, they can opt out by checking the appropriate checkbox on the SSRL SMB Unix account request form (applies upon submittal) or by contacting their support staff. If a group opts out, no results will be recorded in our database or displayed in the Processing Tab, however auto-processing will still be carried out and the results can be found in the auto-processing directories (described below.).
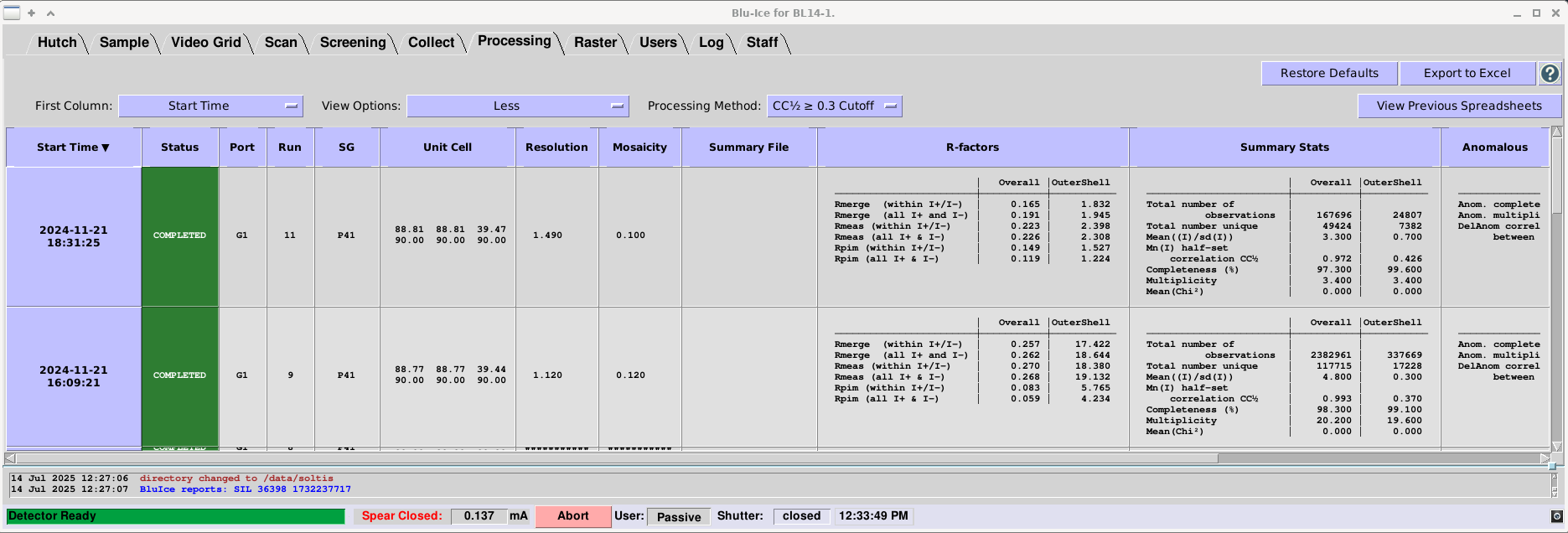
Layout and NavigationEach row displays information and selected results for each data processing run; the table can be quickly traversed using scroll bars or arrow keys. The widths of the table columns can be changed by hovering the mouse pointer near the side of the column. When the pointer turns into a cross, click and drag the side of the column to the desired width. Display OptionsFirst ColumnThis drop down menu allows the user to select the first column which is fixed in place (default: Start Time) - the column stays in view when the table is scrolled horizontally. 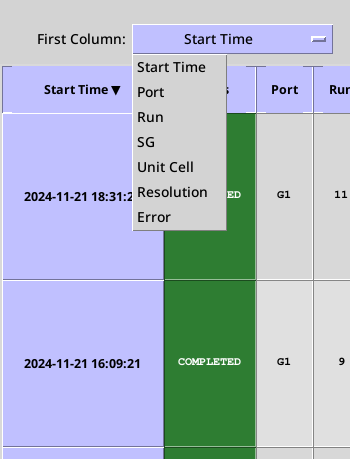
View OptionsThis drop-down menu can be used to select from several displays: Minimum, Less, More, or All:
Processing MethodThis drop-down menu can be used to view the results for different resolution cutoffs (i.e. CC1⁄2, I/σ(I), etc.). Table SortingBy default, the table is sorted on Start Time (when the job was submitted to the queue) and the column is sorted with the last submission on top. However, any column can be used as the primary sorting column by simply clicking on the column title. By clicking on the arrow in the column heading, sorting can be reversed. Two-column sorting is possible by clicking on a second column title anywhere in the spreadsheet which will then become the primary sorting column and the previous sorting column will become the secondary sorting column (similar to how excel works). The primary sorting column is indicated by a solid arrow and the secondary sorting column is indicated by a hollow arrow. ButtonsThe "Restore Defaults" button restores the column default spacing and sorting. The "Export to Excel" button allows the user to download an excel file with all the processing results associated with the spreadsheet. Each processing method is shown on a different sheet. The "View Previous Spreadsheets" button opens a standalone application that allows users to select previous spreadsheets (described in detail below). The “?” button opens a webpage with documentation for the Processing Tab. StatusThe "Status" column indicates the current status of the auto-processing job:
Anomalous Signal DetectionWhen autoPROC detects an anomalous signal, it is reported in the "Anomalous Signal" column and another processing job will be spawned with several anomalous flags set to optimize anomalous data processing.
AnisotropyIn addition to the standard processing method, autoPROC runs an anisotropic analysis and the processing statistics can be flound in the summary.html file under "Anisotropic". The program STARANISO fits an ellipse to the scattering data and the "Anisotropy" parameter in the Processing tab is calculated from the 3 axes of the ellipsoid: Anisotropy = [Max(res1,res2,res3) − Min(res1,res2,res3)] / Ave(res1,res2,res3) An anisotrpy value close to zero indicates no anisotropy in the scattering. However, anisotropies on the order of 0.3 have made significant improvements to electron density maps compared to the standard processing method. Currently, the reported values in the Processing tab (other than mosaicity and anisotropy) are taken from the standard processing output file autoproc.xml. The anistropic values and links to the corresponding anisotropic output files can be found in the summary.html file. Results Summary FileThe "Summary" column will show a path to a summary HTML file (e.g.
How to Interpret Error MessagesIf an error occurs, the Status column will indicate an error and the message will be displayed in the Error column on the Processing Tab. There are two general types of errors:
If there are ICEflow errors, please contact beamline support. autoPROC errors most often reflect issues with processing the data; some of the most common types are:
ICEflow extracts autoPROC error messages from the "top" log file (typically named The autoPROC manual lists a few common errors that can be encountered when running autoPROC as well as a few general suggestions for how to handle them. ICEflow is designed to avoid the more basic errors (for example, all SSRL beamline-specific settings have been implemented already), but if any of these errors crop up, please contact beamline support. Viewing Previous Processing ResultsThere are several ways to view previous results. Within the Blu-Ice Processing Tab, the "View Previous Spreadsheets" button will open a standalone application. If the user is not assigned to a beamline, they can still open the standalone application by either clicking on the Blu-Ice starter icon on the desktop, right clicking on the desktop screen and selecting Applications > Other > Blu-Ice Starter, or thirdly, opening a terminal and typing "go". The Blu-Ice starter window will open and selecting "Auto-Processing Results" will open the standalone application. 
When the application first opens, a list of all spreadsheets associated with the account will be displayed in the Spreadsheets View. 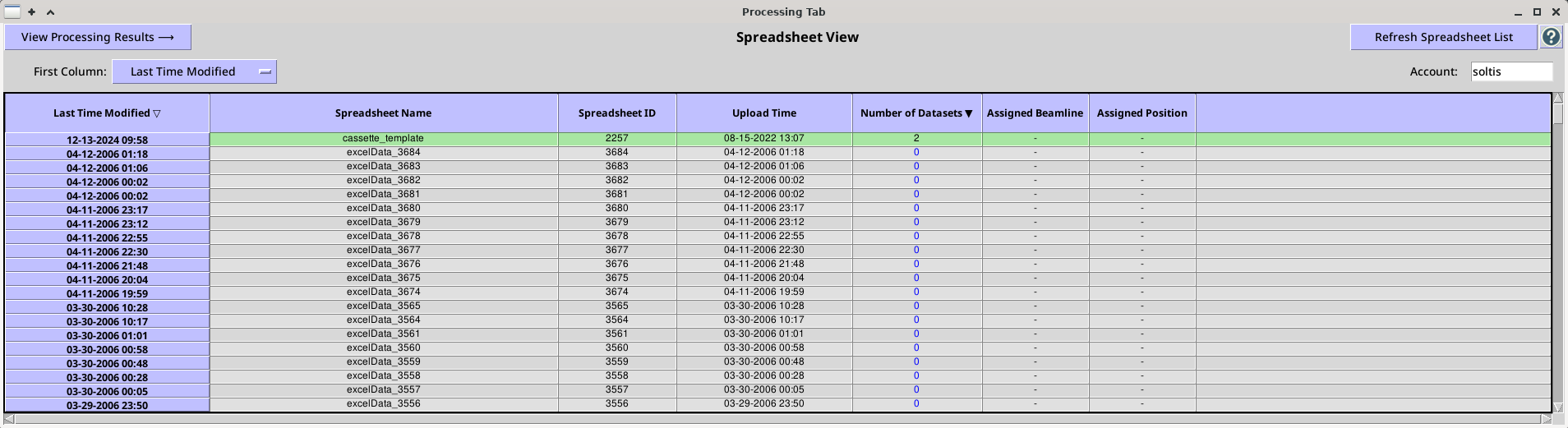
The Spreadsheets View currently displays the Last Time Modified, Spreadsheet Name, Spreadsheet ID, Upload Time and the Number of Datasets associated with a particular spreadsheet. If the selected spreadsheet is currently assigned to a beamline, the last two colums (Assigned Beamline and Assigned Position) will indicate the assigned beamline and the position of the cassette in the robot dewer. To view the processing runs for a particular spreadsheet, highlight a row and click the "View Processing Results" toggle button or simply double click on the row. This will open a standalone Processing Tab for the selected spreadsheet. 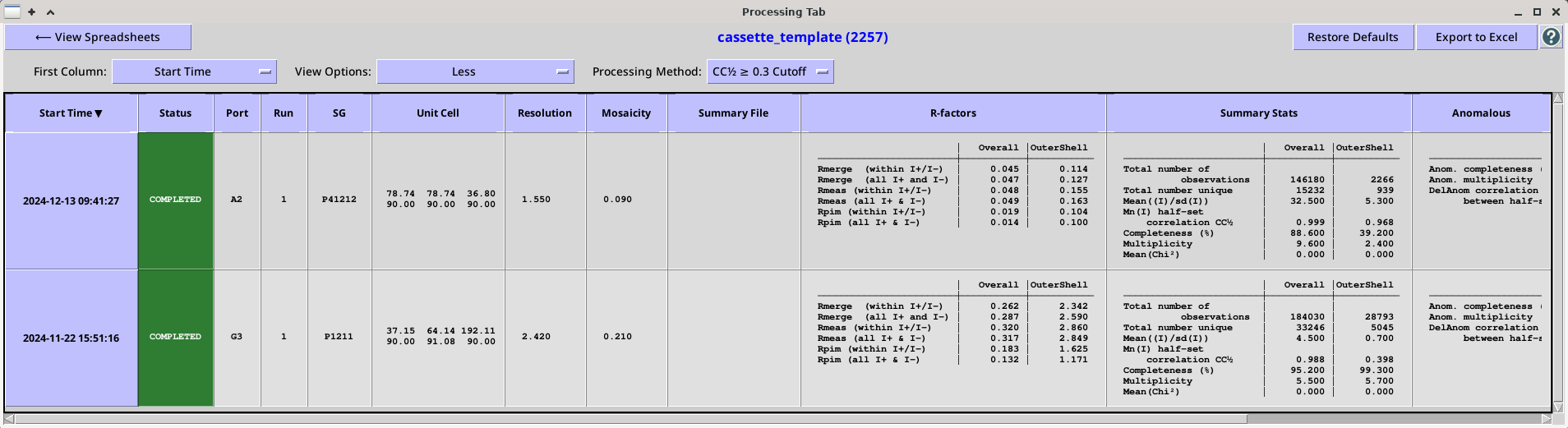
Where Are My Data Located?The data processing directories can be quickly accessed by clicking on the link listed in the "Processing Directory" column when in the View Options "More" or "All". For those groups that have opted out, a symbolic link pointing to a workspace directory can be found in the image directory, for example: When a 2nd job is automatically spawned for enhancing an anomolous signal, a separate workspace directory is used, indicated by incrementing "r#": When a 2nd data collection is run on the same sample and with the same run number, a separate workspace is used, indicated by incrementing "r#". This can occur, for example, whenever a run number is used twice for the same sample: How to Modify the Processing Script and Reprocess Datasets Manually
ICEflow Pipeline (autoPROC)The intial version of ICEflow, deployed autoPROC v1.0.5 in a default configuration. Changes made to the pipeline, 3rd party software, configurations, input parameters, etc. are listed and documented in the next section. Resolution Cutoffs
Programs and Output
Note - for STARANISO anisotropic analysis output files, see the anisotropic section in the summary.html file. XDS.INP - generated automatically by autoPROC - supplies the default parameters to the program
and is based upon information stored in the header of the diffraction images (detector type and distance, oscillation start and range, number of images in the date set, etc.).
The important output files from XDS can be found in the cutoff subfolders, which contain:
References
ICEflow Versions and Release Notes
Pipelines Running before the Inception of ICEflow (before 6/5/2024)For the SSRL pipeline (and the xia2 test pipeline),
look in the image file directory for the symbolic link to the directory with the processed data (these links will all begin with 'autoprocessing').
The processing directory contains the More information on the software supported by the SSRL-SMB Macromolecular Crystallography division is available on our software webpage. |
||
|
|
||
| Technical questions: Webmaster
Content
questions: Aina Cohen |
||
| Last modified:Wednesday, 27-May-2026 12:56:32 PDT. | ||